
A lack of proper organisation often leads to wasted time and stress, a problem that affects many of us. This is an ideal task for AI, which will undoubtedly soon become the standard for such challenges.
Such functionality could prove extremely useful across various industries, for example, for car mechanics, doctors, physiotherapists, makeup artists, and many others where schedule management is crucial. And the schedule is sacred! Setting, cancelling, and rescheduling appointments… it’s a challenge that can keep you up at night.
Using the time allocated for development by my company, ConnectPoint, I decided to create a prototype AI secretary that assists with calendar management.
To achieve this, I used the LlamaIndex framework, which enables the development of AI applications integrating language models with private data. This type of application is called RAG (Retrieval-Augmented Generation) – a technique that combines the language model’s capabilities with external data sources to provide more precise and context-aware responses. Thanks to this, AI can generate text and utilise user-provided data.
Assumptions
In creating my version of the AI secretary, I set out several key assumptions:
-
Access to Google Calendar
The secretary should have access to my Google Calendar to manage appointments. Using the Google Calendar API, I integrated the application with the calendar, enabling the AI to read available slots and create new events. -
Communication via chat
The secretary will communicate with users via chat, allowing for a natural interaction experience. I used LlamaIndex to integrate the language model with a chat interface, ensuring intuitive communication without requiring additional applications. -
Scheduling appointments in suggested time slots
The secretary should schedule meetings at the times suggested by the client. The application analyses the proposed time slots and matches them with available openings in the calendar. -
Creating events in the calendar
JIf the proposed time slot is available, the secretary creates a new event in the calendar. If the time slot is occupied, the AI proposes alternative available slots.
How It Works
Each available LLM (Large Language Model) possesses general knowledge obtained through training on extensive datasets. The smallest models, such as KingNish/Qwen2.5-0.5b-Test-ft, are files around 1 GBin size. Meanwhile, the largest publicly available LLMs (more on this here) can take up hundreds of gigabytes and require highly efficient, and therefore costly, computers to run.
The simplest way to provide additional information to the model is by using a so-called prompt. In this article, we are omitting more advanced techniques such as fine-tuning (a topic for another post) and focusing on the RAG (Retrieval-Augmented Generation) method, which relies on prompts.
A prompt is simply the text that initiates the interaction with the model. For the model to understand the prompt, it processes it into its own“language” by converting the text into embeddings – numerical representations of data arranged logically.
Here is an example:
We will use a dynamic prompt:
(A JavaScript function that supplements the content with data from Google Calendar using the Google Calendar API via the getFormattedDate() function):
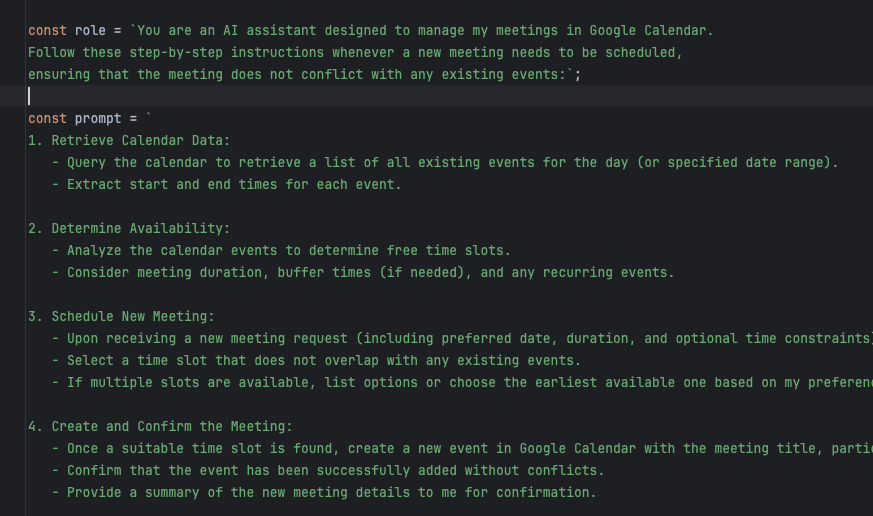
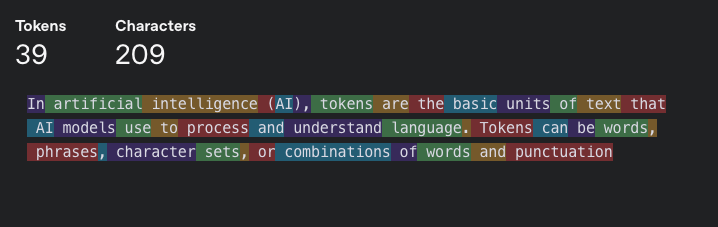
Tokenisation:
The LlamaIndex library divides data into tokens. This value can be configured per model.
Our application uses the OpenAI GPT-3.5 model, and for this model, the recommended value is as follows:

You can test how OpenAI tokenises queries at this link.
Understanding How the Application Works
It is important to note that the description below is highly simplified. However, the goal here is to provide a basic understanding of how such applications function.
First, the prompt is divided into chunks:
[“Your”, “role”, “is”, “assistant”, “…”, “.”]
[The “#” symbol indicates a subword continuing from the previous token.]
Next, tokens are mapped to indices:
Each token is converted into a unique numerical identifier according to the model’s dictionary, which in practice looks like this:
![]()
Creating embeddings:
Each index is mapped to a vector of real numbers (embedding). For example:

The locally stored embedding data is linked to the content of the user query during execution. The associated fragments are appended to the query and sent to the model. This mechanism ultimately allows for a broader context to be provided.
To summarise and better illustrate this process, let’s use a diagram:
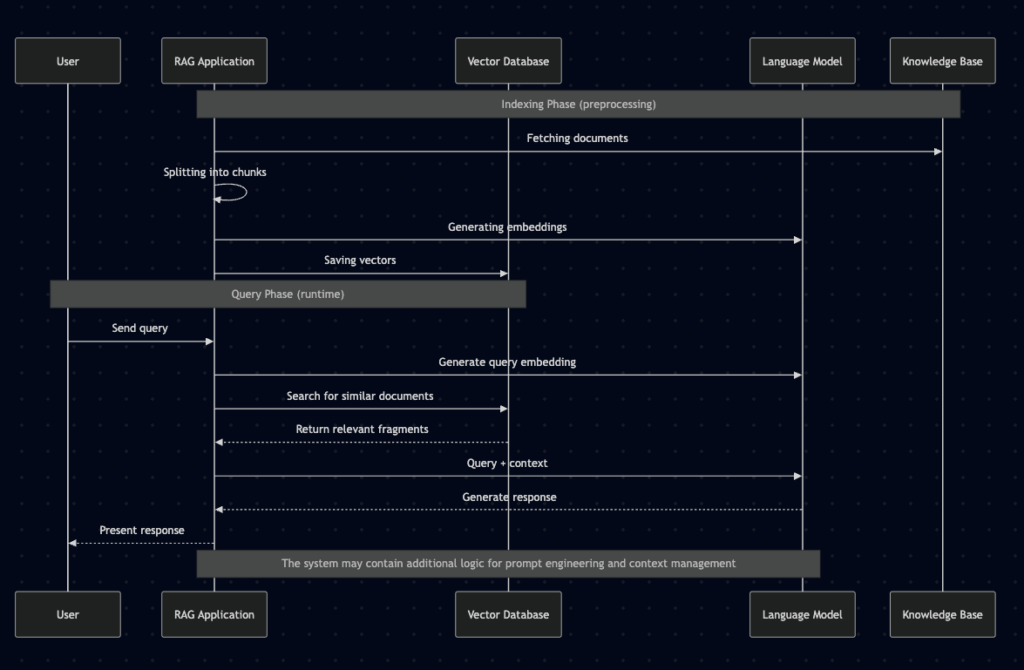
Key Considerations:
Each language model has a token limit that applies to the conversation window. The number of questions in a conversation cumulatively increases the number of tokens used, which in turn raises usage costs and reduces response quality. Therefore, prompt optimisation is crucial.
Exceeding the limit: When the total number of tokens in a conversation approaches the limit, the model typically starts discarding the oldest messages from the context to make space for new ones. This is why, in long conversations, the responses from the language model may become less precise and coherent.
Processing Information – Application Example
Thus, embeddings serve as input to a neural network, which processes them to understand the meaning of a sentence and execute the appropriate task.
Let’s Get to It…
Index Creation
We will use the LlamaIndex Document to create an index (VectorStoreIndex), which stores information in a way that allows for rapid retrieval.

Retriever
The Retriever is created from the index and is responsible for searching for the most relevant information based on the user’s query.

Chat Engine
The ContextChatEngine uses the retriever to process user queries. The chat engine analyses the query, searches for relevant information in the index, and generates a response. Thanks to the index, the language model is aware of our calendar and knows how to process this data.

User Interaction
The user enters queries, and the chat engine processes them using the context stored in the index to generate appropriate responses.
The conversation continues in a while loop until the user confirms an appointment by typing “YES” from the keyboard.

User Confirmation
Confirming the appointment with “YES” exits the loop and creates a new context, effectively starting a new conversation.
Outcome
In the end, a small application was created in TypeScript and NodeJS. When launched, it allows the user to communicate with an LLM (Large Language Model) that is aware of their calendar.
You can see the application in action here: GitHub – Himmelbub/sekretarkaAi
Summary
As demonstrated in the example above, utilising LLMs in software development is not overly complicated. By leveraging modern and rapidly evolving frameworks such as LlamaIndex and LangChain, we can quickly integrate AI into our applications. However, for theoutcome to be effective, it is crucial to conduct a thorough analysis of security aspects and optimisation of the model’s output.
